How to rescue a blog from the Wayback Machine
Or Resurrections, Part One
What do you do when you lose ten years of blog posts? Some of us move on. Try to find a way to live with the loss.
But what if you’re given a chance to bring it back? A chance to reach back in the past, and undo the horrific decimation wrought by Thanos Russian hackers. A chance to make it all right. Whatever it takes.
Okay, so it’s not as dire as all that. But our Wordpress-powered blog had been destroyed—and since all our content was in a database that no longer existed, it seemed like an impossible task to recover everything.
Enter the Wayback Machine.
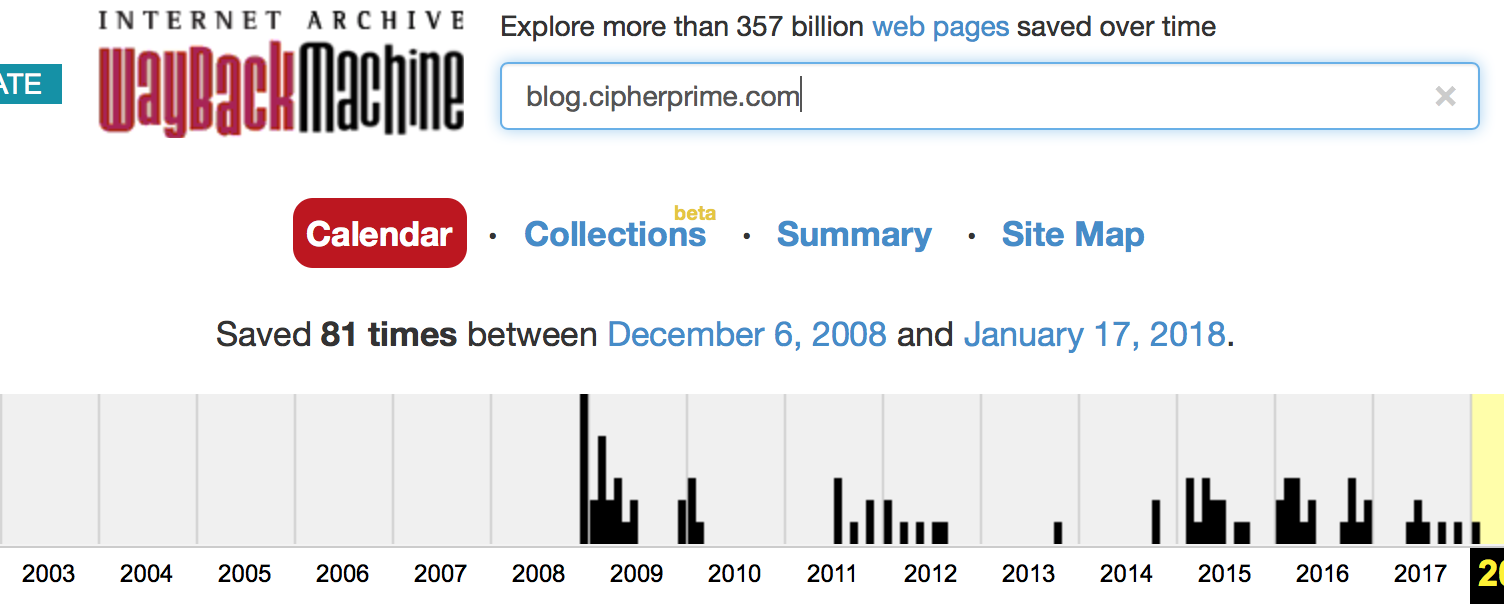
As one of the best parts of the Internet Archive, the Wayback Machine is a magical resource that by all rights shouldn’t exist. Started in 1996, it’s probably one of my favourite things about the internet—good-natured librarians working to preserve ephemeral bits of our history before they’re forgotten forever.
And since our humble little blog happened to get juuust enough traffic to be archived, we were lucky enough to have a snapshot saved from just before the KGB decided our nonsense posts were simply too dangerous to exist.
To download the archive, I used the Wayback Machine Downloader, which after some misadventures in Ruby gave me a nice archive to work from.
Now we had our old blog, in HTML format, with our old permalinks more or less intact in the folder structure. For the new blog, we decided to go for something signficantly more hack-proof—a Jekyll-powered blog hosted on GitHub. Jekyll automatically translates Markdown pages into well-formatted HTML, which is great because:
- Markdown is really easy to write
- GitHub is really secure
- Everything is plain-text, so nothing is stored in a fragile database.
To handle the conversion, I wrote a small NodeJS script to process the downloaded archive. This script crawled each html page, pulled the post and author content out, and put that content in a Markdown template.
I used cli-progress for the snazzy download bars, and image-downloader to handle… downloading images (this got around CORS issues on the command line).
On that note: pulling images out of the archive proved to be a bit trickier, as I had to take each image, find the Wayback resource associated with it, download said resource, then update the image link in our blog. This required a bit of guesswork to find the right root URL the images were saved under. Unfortunately, some of the more recent images hadn’t been online long enough to be archived—those are truly lost, as far as I can tell. But sometimes you have to make a sacrifice to ensure the greatest good. (Sorry, you guys, Endgame was really, really good.)
There’s still some stuff missing from the blog. Tags are saved, but there’s no quick dynamic way to show them, though this post from Long Qian looks promising. And I was able to retrieve old comments, but adding comments to the blog now requires some workarounds, using something like Staticman to handle the updating. This is probably gonna take a minute to get working properly, so in the meantime, we decided to use Disqus—super familiar, super easy to configure, and we might even be able to import the old comments eventually.
In the end, I’m pretty happy with this little experiment! I was really sad when it seemed like we’d lost such a big part of our history, so I was super-stoked to know that nothing’s ever really gone.
Okay, okay, I’ll stop nerding out.
Oh. One last thing—the blog isn’t the only thing getting resurrected. Keep an eye out for some exciting iPad news soon!